AttaCut: Fast and Accurate Word Tokenizer for Thai
Thai language presents unique challenges for natural language processing tasks, including word tokenization. Traditional methods often struggle with accurate and fast word segmentation. However, a breakthrough has been made with AttaCut, a high-performance word tokenizer specifically designed for Thai.
System Architecture
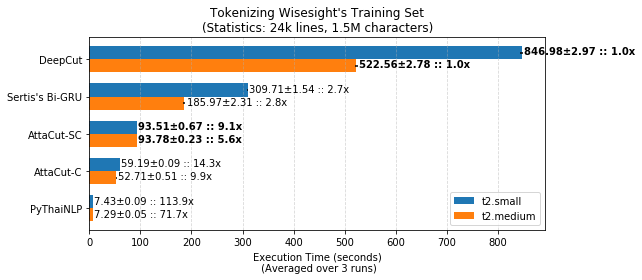
AttaCut utilizes a 3-Layer Dilated Convolutional Neural Network (CNN) that leverages both syllable and character features. This innovative architecture enables AttaCut to achieve remarkable tokenization accuracy and speed. In fact, it is six times faster than the State-of-the-Art DeepCut tokenizer while maintaining a Word Level F1 score of 91% on the BEST dataset, with only a 2% decrease.
Installation and Usage
Installing AttaCut is as simple as running the command:
$ pip install attacut
Note that Windows users need to install PyTorch before executing the installation command. More details can be found on PyTorch.org.
AttaCut provides both a command-line interface (CLI) and a high-level API for easy integration into your projects. The CLI allows you to invoke the tokenizer using the following command:
$ attacut-cli <src> [--dest=<dest>] [--model=<model>]
For more advanced usage, the AttaCut tokenizer can be instantiated directly using the high-level API:
“` python
from attacut import tokenize, Tokenizer
tokenize txt using our best model attacut-sc
words = tokenize(txt)
alternatively, an AttaCut tokenizer might be instantiated directly, allowing
one to specify whether to use attacut-sc or attacut-c.
atta = Tokenizer(model=”attacut-sc”)
words = atta.tokenize(txt)
“`
To ensure maximum efficiency, it is recommended to use attacut-cli for tokenization tasks. For detailed usage examples, refer to our Google Colab tutorial.
Benchmark Results
AttaCut’s performance has been extensively benchmarked, producing impressive results in both tokenization quality and speed. The tokenization quality benchmark demonstrates AttaCut’s accuracy across various domains, as shown here:
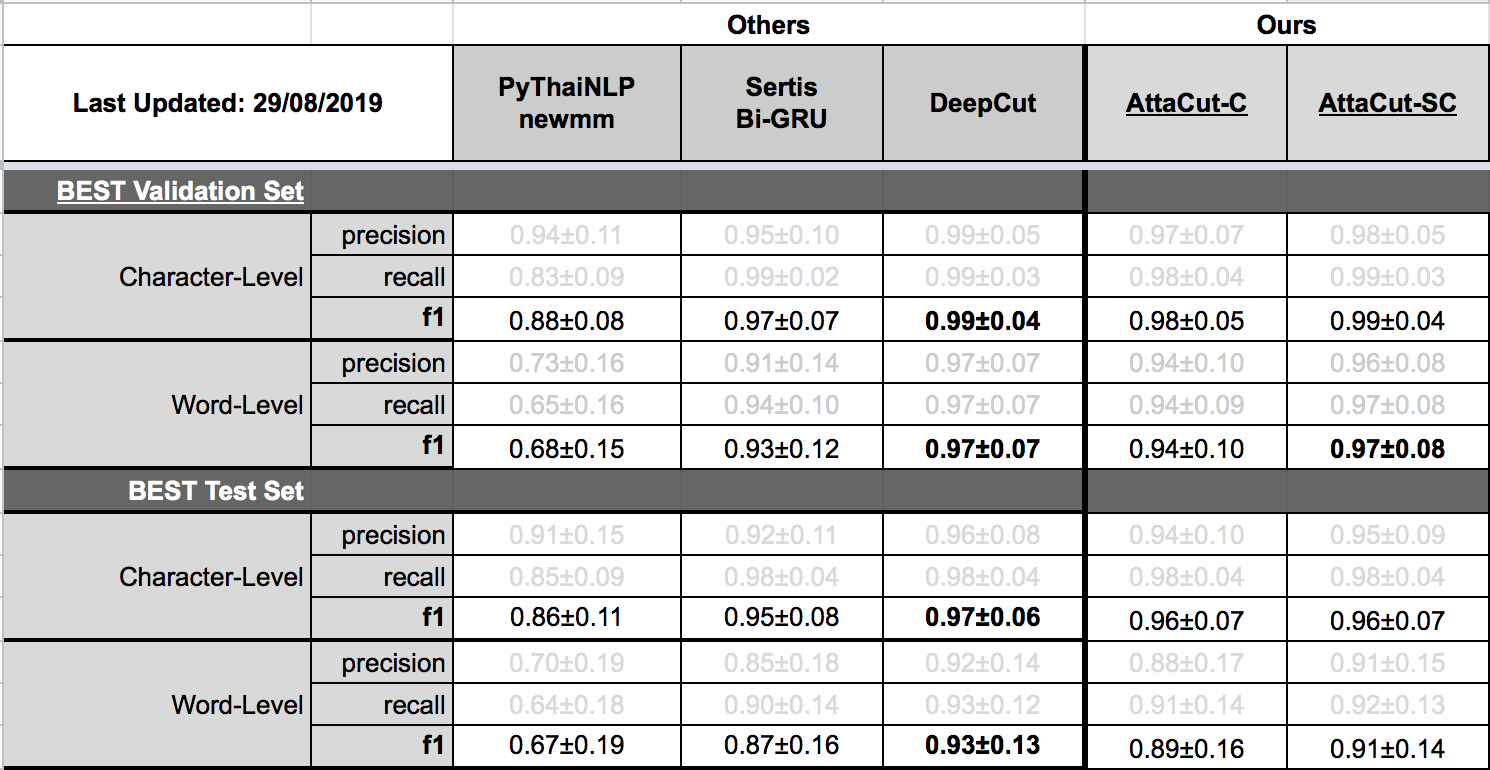
Additionally, AttaCut’s speed benchmark showcases its exceptional performance on EC2 instances:
Retraining on Custom Dataset
For users who wish to customize and retrain AttaCut on their specific datasets, a comprehensive guide is available. Detailed instructions can be found at our retraining page. This feature enables users to adapt AttaCut to domain-specific applications and enhance its performance on specialized datasets.
Related Resources
To further explore AttaCut and its related resources, check out the following:
- Tokenization Visualization: Enhance your understanding of Thai tokenization with interactive visualizations.
- Thai Tokenizer Dockers: Explore Docker images for easy deployment of Thai tokenizers.
Acknowledgements
AttaCut is the result of collaborative efforts by a team of dedicated individuals. Pattarawat Chormai initiated the project during an internship at Dr. Attapol Thamrongrattanarit’s NLP Lab, Chulalongkorn University, Bangkok, Thailand. The development of AttaCut involved the contributions of numerous individuals, with a complete list available in the Acknowledgement section of the documentation.
In summary, AttaCut has revolutionized Thai language processing with its exceptional speed and accuracy. Its system architecture, installation process, and usage have been explored, along with benchmark results and retraining possibilities. By leveraging AttaCut, developers can unlock new possibilities for building Thai natural language processing applications.
Feel free to ask any questions or share your thoughts on AttaCut and its capabilities. Together, let’s embrace the power of language technology and drive innovation in Thai NLP.
Leave a Reply